
You might have heard and been amazed about the fact that DNA is a long list of the letters A, C, G, and T, which make up our genes and those of other species. But what is DNA, and is it indeed made of letters?
Of course they’re not letters. DNA, also famous as DeoxyriboNucleic Acid, is a long chain of molecules–letters serve only as convenient abbreviations for parts of it, similar to how O represents oxygen in our chemical notation. There are no actual letter O’s floating around us–just molecules consisting of two bonded oxygen atoms.
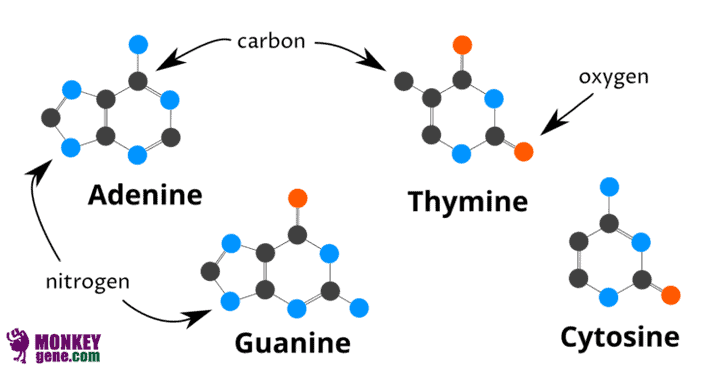
Letters in our genetic code represent small molecules called nucleobases. These molecules come in four different variants.
We know them as Adenine, Cytosine, Guanine, and Thymine. This is what the letters A, C, G, T stand for.
When attached to a sugar molecule, these molecules can form long chains in a specific (sometimes random) sequence. The sequence of these nucleotides determines many things about our bodies, such as our eye color or height and the bodies of other organisms, from bacteria to plants and animals. Such as how tall a tree would grow or how long a giraffe’s neck would become. One such chain forms a single strand of DNA, which is half of what you may recognize as the double helix of DNA.
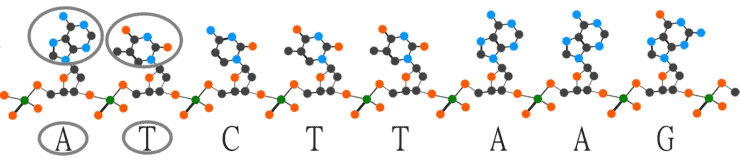
The whole human genome consists of more than three billion nucleobases. Writing them down as A, C, G, T takes a lot less time and hard drive space than referring to them by their full names. Instead of Adenine, Thymine, Cytosine, Thymine, you can simply write ATCT and so on. That’s three billion letters, still a few gigabytes worth of data.
DNA is the template for life
But what work are these letters performing? What difference does it make that they are in one sequence ATCT, versus another, CAGT?
In a general sense, DNA is a genetic template, the instructions given to cells to build the body and run the body as a whole. Each of your cells contains a full copy of your genes and has specific machinery to read them. One of the primary outcomes of this is that the body builds proteins according to these sequences.
So what are proteins, you ask? In short, proteins are widely varying substances that make or run our bodies. Elastin in your skin is a protein. Hemoglobin that delivers oxygen to parts of your body is a protein. Collagen that makes hair and melanin that makes this hair dark are also proteins.
You can learn more about proteins here, but the main thing is that whenever your body needs a protein, it turns on a gene to make it. And when this happens, specific machinery attaches to DNA and slides along it to read the sequence in which the building blocks of proteins should go. For simplicity, I will ignore the fact that proteins are made from DNA in several steps.
Proteins are chains of building blocks (amino acids–but don’t worry about the term now). There aren’t that many different types of these building blocks, but they can make an endless variety of proteins, just like a Lego set consists of a limited variety of bricks but can actually make an endless number of different creations. They’re different not because the building blocks are different, but because the places where each block goes are different.
Thus, DNA is, in essence, an instruction manual that gives instructions as to the proper sequence of the building blocks. The process of how DNA transforms into proteins is quite exciting, and I shall cover it in one of my upcoming articles.
How DNA carries hereditary information
You may have also heard that DNA is the basis for heredity. If you have your mother’s nose, it is in your genes, right? Well, yes, and, despite this being an oversimplification, it comes from the fact that you inherited your mother’s template of building a nose.
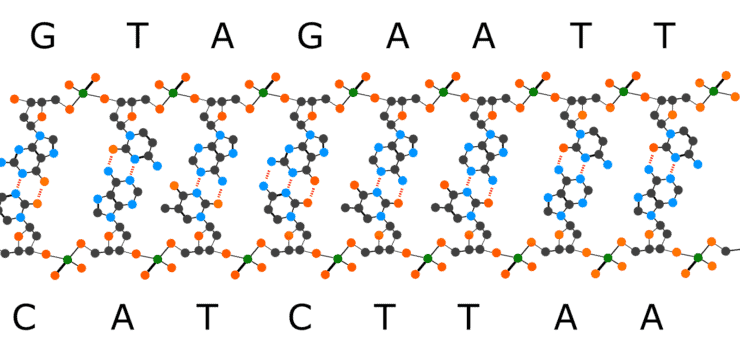
As mentioned above, DNA consists of not one but two strings–a “double helix.” Both strands are firmly glued to each other, and one thing you’ll notice is that C always pairs with G and A with T.
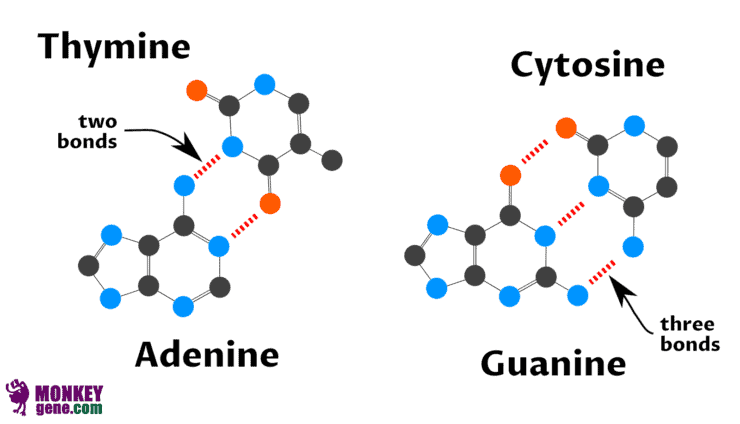
This is caused by the fact that the adenine and thymine are equipped with two sites that can attach to each other, but cytosine and guanine have three sites. These sites of attachments are in convenient positions so that if you place T next to G, they won’t glue together well, whereas setting C against G or A against T does the trick.
A happy consequence of this is that the replicating machinery in your cells can copy the whole double helix. It unzips the double helix and detaches both strings and then places a new G next to each C or a new A next to each T. Thus, brick by brick, it assembles a complementary DNA string.
What you end up with is not one, but two identical double helices. Well, not exactly identical, because mistakes happen. We call these mutations, but that is not a topic for today.
Once the double helices are copied, the cell can divide in two. This is what cells typically do. But in a special case, one of these new cells becomes a sex cell–a sperm or an ova. There is a whole story behind this as well, but each of the sex cells contains the DNA. That, as you know, is a template for building our bodies, including the nose that you got from your parent.